Zero-Knowledge Machine Learning (zkML)
An end-to-end workflow depicting how to use ezkl to generate and verify zero knowledge proofs for ML model outputs
Introduction
In our context, Zero-Knowledge Machine Learning (zkML) is the ability to verifiably prove that a given prediction did indeed come from a certain machine learning (ML) model claimed so by the modeler who trained that ML model.
There are two main players in the zkML game:
- prover, who testifies that a given prediction is the output of a certain ML model
- verifier, who verifies the correctness of the above proof
Please refer to this post for a detailed primer on zkML.
zkML in Practice
Practically speaking, all zkML approaches convert a trained ML model (M) into its equivalent zk-circuit representation (M'). Since the zk-circuit works with integers while floating point numbers are used in traditional ML techniques, there's bound to be a difference between the results of the ML model and its equivalent zk-circuit representation.
M' resembles M in terms of the architecture but differs in terms of the resultant model accuracy since:
- All operations within M' are performed after quantizing all the involved tensors.
- In essence, quantization converts all floating point numbers to integers → directly impacting M''s accuracy (at the benefit of smaller size and faster inference time)
zkML then proves and verifies that M was quantized which then produced a certain output after passing the quantized input feature vector through M'.
Concretely, given a ML model M that outputs y:
- zkML converts
Mto a quantized zk circuitM' M'produces an outputy'- zkML proves that the
y'did indeed come from M' - The difference between
yandy'is known as the Quantization Error
The above might appear to be counterintuitive to a traditional ML practitioner/data scientist, however:
- This is in-line within the zkML landscape and is widely accepted by zkML practitioners
- All ML models (specifically large models deployed on Edge devices) have to be transformed in one way or the other to allow:
- for real-time or near-real-time predictions
- them to be compatible with prod tech-stack and the edge devices
Such transformations indeed change the predicted values in production/real-time environment compared to those in the dev/modelling environment.
- Requires a mindset shift and general acceptance from the traditional ML practitioners whereby one needs to be willing to accept a level of compromise to implement zkML on top of their ML models and make their predictions zk-verifiable.
We require Modelers to use y' for all predictions returned during production.
Recommendation
We recommend calculating the quantization error of your trained model (using the provided sample code, tailored to your circumstances) and making sure that the average of absolute errors across a handful of observations is not too high. If it is too high then experiment with another model architecture (with different operations) or adjust your zkML setup as explained in the Calibrate Settings section below.
Note that using the resources calibration in ezkl.calibrate_settings() will generally result in reasonable quantization errors, however there are certain operations (e.g., BatchNorm1d) that will result in a higher quantization error compared to the models that don't include such operations.
zkML Library
Credio has partnered with Zkonduit to allow the generation and verification of verifiable Zero-Knowledge Proofs on its platform. ezkl, one of Zkonduit’s zkML project, allows modelers to create zero-knowledge proofs of machine learning models imported using the Open Neural Network Exchange (ONNX).
Please refer to ezkl’s GitHub repo for further details, including some demo Jupyter Notebooks.
Overview of the zkML Workflow - using ezkl
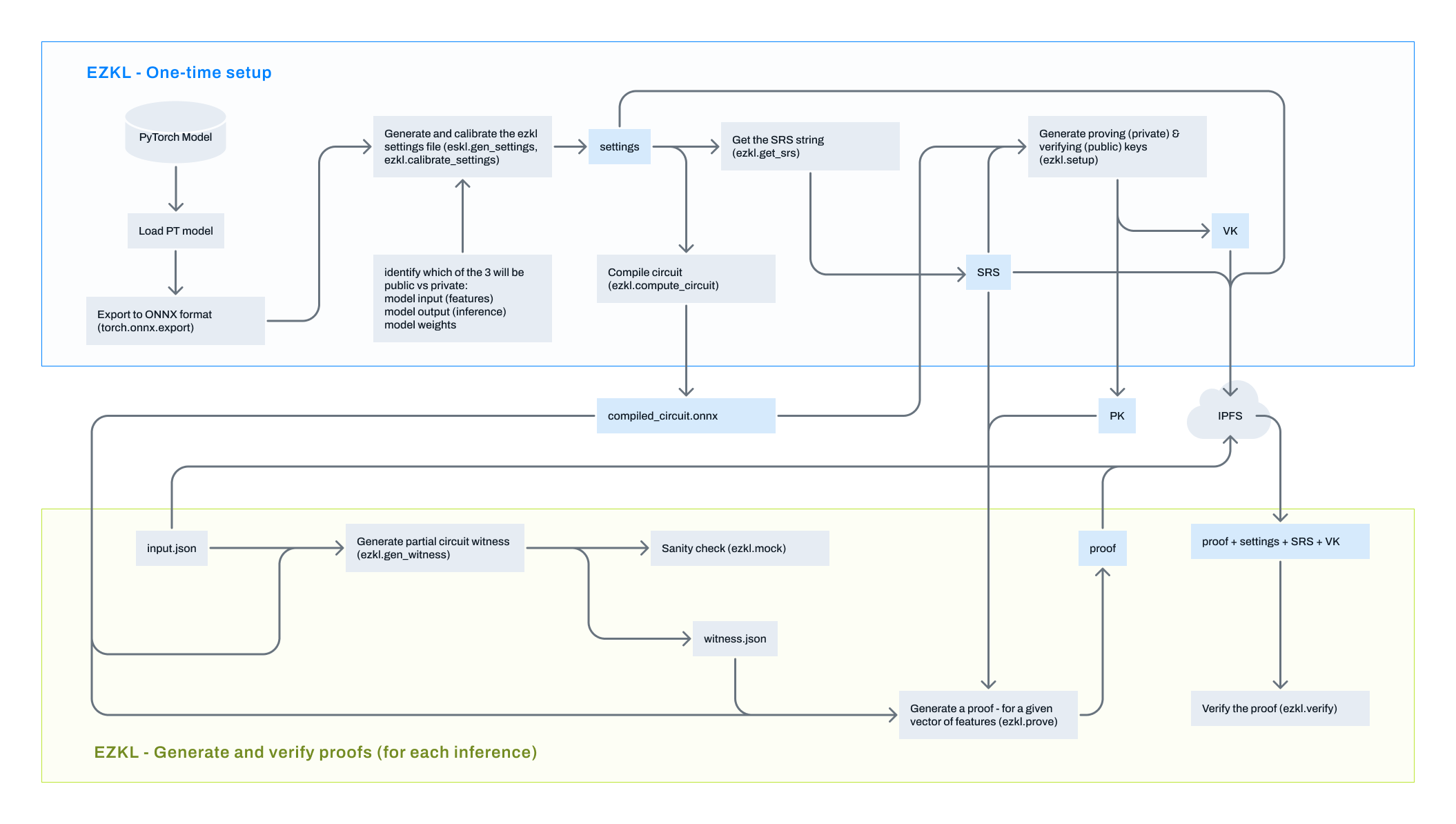
At a high level, the end-to-end zkML workflow comprises of:
Setup
-
Train a ML model
- PyTorch is natively supported and is thoroughly tested
- Support for scikit-learn decision trees, random forests, and XGBoost has been recently added
-
Export the trained ML model to the ONNX format through
torch.onnx.export() -
Generate and calibrate a JSON settings file through
ezkl.generate_settings()andezk.calibrate_settings()respectively. These settings will then be used to create a quantized Halo2 circuit to represent the underlying ML model- Settings file is to be shared with the verifier
-
Compile the ONNX model through
ezkl.compile_circuit() -
Fetch the Structured Reference String (SRS) required for zkML
- SRS file is to be shared with the verifier
-
Setup ezkl through
ezkl.setup()to create the proving and verifying keys- Verifying key is to be shared with the verifier
Proof Generation
- Generate a witness file through
ezkl.gen_witness() - Perform a mock run through
ezkl.mock()as a sanity check of the steps performed so far - Generate a proof for a given model output through
ezkl.prove() - Proof file is to be shared with the verifier
Proof Verification
- Verify a proof through
ezkl.verify()
ezkl Detailed Workflow - using PyTorch
Model Training
Train a PyTorch model as you would usually do.
Export to ONNX
Inputs required
- Trained PyTorch Model
- A random tensor of the same shape as the model input feature vector
- Path where to save the resultant ONNX model
Output
- ONNX model
Sample code
import onnx
import torch
# put the trained model in the eval mode
model.eval()
torch.onnx.export(model=model, # trained model
args=torch.randn((1,41), requires_grad = True), # random tensor of the same shape as expected by the model
f="model.onnx", # Path location where to save the ONNX file
input_names=["input"], # model input name
output_names=["output"], # model output name
dynamic_axes={"input" : {0 : "batch_size"}, # variable length axes
"output" : {0 : "batch_size"}})
Install ezkl
Installing ezkl is as simple as pip install ezkl.
Generate Settings
Inputs Required
model: The saved ONNX model from the previous stepoutput: Path where to save the resultant settings filepy_run_args: Some of the key arguments for ezkl that can be specified are the following:input_visibility: has to be public in our use case, i.e., the model inputs are publicly known. The quantized field vector representation of these inputs are included in the proof file.output_visibility: has to be public in our use case, i.e., the model output is publicly known. The quantized field vector representation of the output is included in the proof file.param_visibility: has to be public in our use case, i.e., the trained model’s parameters are effectively baked into the zk-circuit and cannot be altered by the prover post -proof generation. However, the model parameters are not visible in the proof file shared with the verifierbatch_size: has to be 1 in our use case, i.e., proof for a single prediction is to be generated
Output
A JSON settings file. These settings dictate the parameters required to generate the zk-circuit.
Sample Code
# define arguments
run_args = ezkl.PyRunArgs()
run_args.input_visibility = "public"
run_args.param_visibility = "public"
run_args.output_visibility = "public"
run_args.variables = [("batch_size", 1)]
# generate settings
try:
res = ezkl.gen_settings(model="model.onnx",
output="settings.json",
py_run_args=run_args)
if res:
print("Settings were successfully generated")
except Exception as e:
print(f"An error occurred: {e}")
Calibrate Settings
Inputs Required
data: A JSON file containing a dictionary of the feature values with a key of input_data. The dictionary values could either be a single set of feature values or multiple, all concatenated into a single list. These feature values will be used to calibrate the settings, therefore, they need to be as representative of the feature values as expected in the production (scaled values if the model expects to receive scaled values). The more data fed to calibrate_settings the more accurate (lower quantization errors) the resultant zk-circuit will be, albeit potentially at the cost of higher compute and memory requirements and longer proving times.
Sample data format
{"input_data": [[obs_1_feature_1, ..., obs_1_feature_n, obs_2_feature_1, ..., obs_2_feature_n, ..., obs_n_feature_1, ..., obs_n_feature_n]]}
model: The saved ONNX model from one of the previous stepssettings: Settings file generated in the previous steptarget: accepts one of the following values:resources: Settings are calibrated to optimize the compute and proving time requirements together with smaller proof + proving key + verifying key file sizes at the cost of a relatively higher quantization erroraccuracy: Settings are calibrated to minimize the quantization error at the cost of higher compute requirements, longer proving times, and much larger proof + proving key + verifying key file sizes
Refer to the Quantization Error section below for further details.
Output
- Calibrated JSON settings file (the original settings file provided to settings is overwritten)
Sample Code
# import dependencies
import json
# serialize the data to be used for calibration
input_data_np = input_data_tensor.numpy().tolist() # 1 or multiple tensors concatenated into a single list
input_data_dict = dict(input_data = [input_data_np])
json.dump(input_data_dict, open("input.json", "w"))
# calibrate the settings file
try:
res = await ezkl.calibrate_settings(data="input.json",
model="model.onnx",
settings="settings.json",
target="resources")
if res:
print("Settings were successfully calibrated")
except Exception as e:
print(f"An error occurred: {e}")
Notes
A fine balance needs to be achieved between the following:
- compute requirements, proving time, and file sizes of the proof, verifying key, and proving key
- quantization error
Strategies to find the right balance:
- try both
resourcesandaccuracyfor the target argument - manually adjust the
input_scale,bits, andlogrowsarguments in the generated settings file
Generally speaking, higher values for input_scales is required for larger & more complex models or where minimal quantization error is required. These higher input_scales values tend to require larger lookup tables → more bits to infill the lookup tables → requires more logrows → results in larger proving key file sizes → longer proving times.
ezkl Compile the zk-circuit
Inputs required
model: The saved ONNX model from one of the previous stepscompiled_circuit: Path where to save the resultant ezkl compiled zk-circuitsettings_path: JSON of the calibrated settings file from the previous step
Output
- Compiled zk-circuit, inclusive of the settings
Sample Code
# compile model
try:
res = ezkl.compile_circuit(model="model.onnx",
compiled_circuit="compiled_circuit.onnx",
settings_path="settings.json")
if res:
print("Model was successfully compiled")
except Exception as e:
print(f"An error occurred: {e}")
Fetch SRS
Input required
srs_path: Path where to save the resultant SRS filesettings_path: JSON of the calibrated settings file from one of the previous steps
Output
JSON of the SRS
Sample code
# get the SRS string
try:
res = ezkl.get_srs(srs_path="kzg.srs",
settings_path="settings.json")
if res:
print("SRS was successfully fetched")
except Exception as e:
print(f"An error occurred: {e}")
Setup ezkl
Inputs required
model: ezkl compiled zk-circuit from one of the previous stepsvk_path: Path where to save the resultant verifying keypk_path: Path where to save the resultant proving keysrs_path: JSON of the SRS generated in the previous step
Output
- Proving key
- Verifying key
Sample code
# ezkl setup - to generate PK and VK
try:
res = ezkl.setup(model="compiled_circuit.onnx",
vk_path="model_vk.vk",
pk_path="model_pk.pk",
srs_path="kzg.srs")
if res:
print("ezkl's setup was successful")
except Exception as e:
print(f"An error occurred: {e}")
Generate Witness file
Inputs required
data: JSON of the input feature vector for which a proof is to be generated
Sample data
{"input_data": [[feature_1, feature_2, ..., feature_n_1, feature_n]]}
model: ezkl compiled zk-circuit from one of the previous stepsoutput: Path where to save the resultant witness file
Output
- JSON of the witness file
Sample code
# generate witness file
try:
res = ezkl.gen_witness(data="input.json",
model="compiled_circuit.onnx",
output="witness.json")
if res:
print("Witness file was successfully generated")
except Exception as e:
print(f"An error occurred: {e}")
Mock Run
Inputs required
witness: JSON of the witness file from the previous stepmodel: ezkl compiled zk-circuit from one of the previous steps
Output
- Binary flag whether the mock run was successful or not
Sample code
# mock proof for sanity check
try:
res = ezkl.mock(witness="witness.json",
model="compiled_circuit.onnx")
if res:
print("Mock proof run was successful")
except Exception as e:
print(f"An error occurred: {e}")
Generate a Proof
Inputs required
- 'witness': JSON of the witness file from one of the previous steps
- 'model': ezkl compiled zk-circuit from one of the previous steps
- 'pk_path': Proving Key from one of the previous steps
- 'proof_path': Path where to save the resultant proof file
- 'srs_path': JSON of the SRS from one of the previous steps
- 'proof_type': whether a single or an aggregated proof is required. possible values: single and for-aggr
Output
- proof file
Sample code
# generate proof
try:
res = ezkl.prove(witness="witness.json",
model="compiled_circuit.onnx",
pk_path="model_pk.pk",
proof_path="proof.pf",
srs_path="kzg.srs",
proof_type="single")
if res:
print("Proof was successfully generated")
except Exception as e:
print(f"An error occurred: {e}")
Proof Verification
Inputs required
proof_path: Proof file generated from the previous stepsettings_path: JSON of the calibrated settings file from one of the previous stepsvk_path: Verifying Key from one of the previous stepssrs_path: JSON of the SRS from one of the previous steps
Output
Binary flag whether the proof verification was successful or not
Sample code
# verify proof
try:
res = ezkl.verify(proof_path="proof.pf",
settings_path="settings.json",
vk_path="model_vk.vk",
srs_path="kzg.srs")
if res:
print("Proof was successfully verified")
except Exception as e:
print(f"An error occurred: {e}")
Calculate Quantization Errors
It is fairly straightforward to calculate and analyze the quantization error for multiple input feature vectors. The process essentially involves determining the zk-circuit output and that of the underlying ML model and comparing the difference between these two. For a trained PyTorch model converted to an ONNX model that outputs predicted logits for a given input feature vector, the following code can be used to quantify the quantization error across multiple observations:
# import dependencies
import ezkl, json, onnx, onnxruntime
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# setup the settings file for ezkl
run_args = ezkl.PyRunArgs()
run_args.input_visibility = "public"
run_args.param_visibility = "public"
run_args.output_visibility = "public"
run_args.variables = [("batch_size", 1)]
def generate_settings(model):
# generate the settings file
try:
res = ezkl.gen_settings(f"{model}.onnx",
"settings.json",
py_run_args=run_args)
except Exception as e:
print(f"An error occurred: {e}")
async def calibrate_settings(model, input_file):
# calibrate the settings file
try:
res = await ezkl.calibrate_settings(f"{input_file}.json",
f"{model}.onnx",
"settings.json",
"resources")
except Exception as e:
print(f"An error occurred: {e}")
def compile_circuit(model):
# compile model
try:
res = ezkl.compile_circuit(f"{model}.onnx",
f"compiled_{model}.onnx")
except Exception as e:
print(f"An error occurred: {e}")
def gen_witness(model, input_file):
# generate witness file
try:
res = ezkl.gen_witness(f"{input_file}.json",
f"compiled_{model}.onnx",
"witness.json")
if res:
return res
except Exception as e:
print(f"An error occurred: {e}")
def get_ezkl_output(witness_output, settings_file):
# convert the quantized ezkl output to float value
outputs = witness_output["outputs"]
with open(settings_file) as f:
settings = json.load(f)
ezkl_output = ezkl.vecu64_to_float(outputs[0][0], settings["model_output_scales"][0])
return ezkl_output
def get_onnx_output(model, input_file):
# generate the ML model output from the ONNX file
onnx_model = onnx.load(f"{model}.onnx")
onnx.checker.check_model(onnx_model)
with open(f"{input_file}.json") as f:
inputs = json.load(f)
inputs_onnx = np.array(inputs["input_data"]).astype(np.float32)
onnx_session = onnxruntime.InferenceSession(f"{model}.onnx")
onnx_input = {onnx_session.get_inputs()[0].name: inputs_onnx}
onnx_output = onnx_session.run(None, onnx_input)[0][0][0]
return onnx_output
def compare_outputs(zk_output, onnx_output):
# calculate percentage difference between the 2 outputs
return ((onnx_output/zk_output) - 1) * 100
# generate and calibrate settings - assuming that the trained model is called 'model' and the input
# data required for calibration is saved as 'input.json'
generate_settings("model")
await calibrate_settings(model="model", input_file="input") # '.json' is omitted as it's part of the function
# ezkl compile model
compile_model("model")
# instantiate empty lists to store predictions and differences
ezkl_pred_output_list_model = []
onnx_pred_output_list_model= []
perc_diff_output_list_model= []
# loop over 3,000 input files (customizable as per your requirements) and calculate the quantization error for each corresponding prediction
# all 3k input files are saved as input_1, input_2, etc.
for i in range(3000):
witness = gen_witness(model="model", input_file=f"input_{i}")
ezkl_output = get_ezkl_output(witness_output=witness, settings_file="settings.json")
onnx_output = get_onnx_output(model_v="model", input_file=f"input_{i}")
# there may be edge cases where ezkl_output = 0. If yes, then handle them appropriately
if ezkl_output != 0:
perc_diff = compare_outputs(zk_output=ezkl_output, onnx_output=onnx_output)
onnx_pred_output_list_model.append(onnx_output)
ezkl_pred_output_list_model.append(ezkl_output)
perc_diff_output_list_model.append(perc_diff)
elif ezkl_output == 0 and onnx_output - ezkl_output < 0.1:
ezkl_output = onnx_output
perc_diff = compare_outputs(zk_output=ezkl_output, onnx_output=onnx_output)
onnx_pred_output_list_model.append(onnx_output)
ezkl_pred_output_list_model.append(ezkl_output)
perc_diff_output_list_model.append(perc_diff)
# calculate absolute min, max, mean, & median
print(f"Absolute Minimum: {pd.Series(perc_diff_output_list_model).abs().min():.2f}%")
print(f"Absolute Maximum: {pd.Series(perc_diff_output_list_model).abs().max():.2f}%")
print(f"Absolute Average: {pd.Series(perc_diff_output_list_model).abs().mean():.2f}%")
print(f"Absolute Median: {pd.Series(perc_diff_output_list_model).abs().median():.2f}%")
# plot a histogram
plt.hist(pd.Series(perc_diff_output_list_model), bins=50)
plt.xlabel("Quantization Error (%age)")
plt.ylabel("Count")
plt.title("model");
Credit: This article was originally published by Spectral